
El Machine Learning (ML) está transformando múltiples sectores al permitir que los sistemas informáticos aprendan y tomen decisiones basadas en datos. Desde detectar fraudes financieros hasta personalizar recomendaciones de productos, las técnicas de ML son clave para la innovación y la eficiencia operativa. Este artículo examina los distintos tipos de machine learning, sus aplicaciones prácticas, y los beneficios y desafíos que presenta cada enfoque. Comprender las capacidades de cada tipo de ML permite a las empresas utilizar estas tecnologías de manera más efectiva para resolver problemas complejos y obtener información valiosa.
¿Qué es el Machine Learning?
Machine Learning es una rama de la inteligencia artificial (IA) que consiste en crear algoritmos y modelos estadísticos que permitan a los ordenadores realizar tareas específicas sin estar explícitamente programados para ello. En otras palabras, en lugar de seguir instrucciones detalladas paso a paso, los ordenadores aprenden a partir de datos y experiencias pasadas. Esto les permite hacer predicciones o tomar decisiones basadas en nuevos datos.
La idea principal detrás del ML es que los sistemas pueden identificar patrones y correlaciones desconocidos en grandes cantidades de datos y, con el tiempo, mejorar su capacidad para realizar tareas específicas. El aprendizaje se realiza alimentando grandes conjuntos de datos y utilizando algoritmos que ajustan los modelos para representar mejor las relaciones entre ellos.
Tipos de Machine Learning
Existen varios tipos de machine learning, que pueden clasificarse en cuatro categorías principales:
- Aprendizaje supervisado: En el aprendizaje supervisado, el algoritmo se entrena en un conjunto de datos etiquetados. Esto significa que cada ejemplo de entrenamiento está compuesto por un conjunto de inputs y outputs debidamente identificados y clasificados. El objetivo del algoritmo es aprender a mapear la relación entre las entradas (inputs) y salidas (outputs) basándose en los ejemplos proporcionados;
- Aprendizaje no supervisado: En el aprendizaje no supervisado, el algoritmo se entrena en datos sin etiquetas. El objetivo es descubrir estructuras ocultas en los datos. Sin respuestas, el algoritmo intenta agrupar o reducir la dimensionalidad de los datos para extraer insights potencialmente relevantes;
- Aprendizaje semi-supervisado: El aprendizaje semi-supervisado es un enfoque intermedio que utiliza tanto datos etiquetados como datos no etiquetados para entrenar algoritmos. Normalmente, se utiliza una pequeña cantidad de datos etiquetados junto con una gran cantidad de datos no etiquetados. Es útil cuando la etiquetación de datos es costosa o lleva mucho tiempo;
- Aprendizaje por refuerzo: En el aprendizaje por refuerzo, en lugar de correlacionar las variables de entrada con los parámetros de salida, el algoritmo aprende a tomar decisiones mediante la interacción con un entorno dinámico. Recibe recompensas o castigos en función de las acciones que realiza, y el objetivo es maximizar la recompensa acumulada a lo largo del tiempo.

Estos tipos de machine learning permiten la aplicación de técnicas de ML en una amplia gama de problemas, desde la previsión financiera hasta la creación de sistemas autónomos.
Aprendizaje supervisado
El aprendizaje supervisado es uno de los enfoques más comunes y utilizados en el campo del machine learning. En esta técnica, los algoritmos se entrenan utilizando un conjunto de datos etiquetados, en el que cada entrada está asociada a una salida deseada. El objetivo es que el modelo aprenda a partir de estos ejemplos para que pueda hacer predicciones o tomar decisiones precisas cuando se presenten nuevos datos.
Aplicaciones del aprendizaje supervisado
El aprendizaje supervisado tiene una amplia gama de aplicaciones en diversos sectores, entre las que se incluyen:
- Clasificación de e-mails de spam: Identificar correos no deseados y clasificarlos como spam o no spam;
- Detección de fraudes: Identificar transacciones fraudulentas en tiempo real en sistemas financieros;
- Reconocimiento y clasificación de imágenes: Clasificar imágenes en categorías, como identificar objetos o caras en fotos;
- Predicción de ventas: Prever el volumen de ventas futuras basándose en datos históricos;
- Análisis de sentimientos: Determinar el sentimiento (positivo, negativo o neutro) de textos, como reseñas de productos o comentarios en redes sociales;
- Sistemas de recomendación: Sugerir productos o contenidos basados en el historial de preferencias de los usuarios;
- Conversión de voz a texto: Convertir el lenguaje hablado en texto escrito;
- Diagnóstico médico: Ayudar en la identificación de enfermedades basándose en síntomas y pruebas médicas.
Ventajas
El aprendizaje supervisado ofrece varias ventajas, entre las que destacamos:
- Precisión: Los modelos supervisados pueden ser muy precisos, siempre que se entrenen con datos de buena calidad;
- Versatilidad: Puede aplicarse a una amplia gama de problemas de clasificación y regresión;
- Interpretación: Los procesos de toma de decisiones suelen ser fáciles de interpretar y explicar.
Desafíos
A pesar de sus ventajas, el aprendizaje supervisado también presenta algunos desafíos:
- Necesidad de datos etiquetados: Requiere una gran cantidad de datos etiquetados, cuya obtención puede resultar costosa y requerir mucho tiempo;
- Overfitting: Existe el riesgo de que el modelo se ajuste demasiado a los datos de entrenamiento, lo que perjudica su rendimiento con nuevos datos;
- Bias en los datos: Si los datos de entrenamiento están sesgados, el modelo resultante también estará sesgado;
- Actualización de modelos: Los modelos pueden necesitar actualizarse regularmente con nuevos datos para mantener la precisión.
Aprendizaje no supervisado
El aprendizaje no supervisado es un enfoque del machine learning en el que los algoritmos se entrenan utilizando datos que no etiquetados. A diferencia del aprendizaje supervisado, em el que cada entrada tiene una salida correspondiente conocida, en el aprendizaje no supervisado el objetivo es identificar patrones o estructuras ocultas en los datos. Esto puede incluir la agrupación de datos en categorías o la reducción de la dimensionalidad de los datos para simplificarlos y visualizarlos. Las dos categorías principales de aprendizaje no supervisado son el clustering y las reglas de asociación.
Aplicaciones del aprendizaje no supervisado
El aprendizaje no supervisado se utiliza ampliamente en varias áreas, incluyendo:
- Agrupación de clientes: Segmentar clientes en grupos con comportamientos o características similares para estrategias de marketing dirigidas;
- Recomendación de productos: Descubrir patrones de compra que ayudan a sugerir productos relevantes a los usuarios;
- Análisis de comunidades en redes sociales: Identificar comunidades e personas influyentes en las redes sociales mediante el análisis de la estructura de las conexiones entre los usuarios;
- Detección de anomalías: Identificar transacciones inusuales o fraudulentas que no se ajustan a los patrones normales de los datos;
- Compresión de datos: Reducir la dimensionalidad de los datos para facilitar su almacenamiento y análisis, como las técnicas de compresión de imágenes;
- Análisis genético: Identificar patrones en secuencias de ADN para la investigación genética y biomédica.
Ventajas
El aprendizaje no supervisado presenta varias ventajas:
- Exploración de datos: Permite la identificación de patrones ocultos e insights en datos no etiquetados;
- Reducción de costes: No requiere datos etiquetados, ahorrando tiempo y recursos necesarios para la etiquetación manual;
- Adaptabilidad: Puede aplicarse a nuevos conjuntos de datos sin necesidad de etiquetas, haciéndolo flexible para diferentes aplicaciones;
- Identificación de anomalías: Eficaz en la detección de outliers y anomalías que pueden no ser evidentes en datos etiquetados.
Desafíos
Sin embargo, el aprendizaje no supervisado también afronta desafíos:
- Interpretación de resultados: Los resultados pueden ser difíciles de interpretar, ya que no hay etiquetas que validen las conclusiones;
- Complejidad computacional: Los algoritmos pueden ser complejos desde el punto de vista computacional, especialmente para grandes conjuntos de datos;
- Calidad de los datos: La eficacia depende de la calidad y representatividad de los datos de entrada;
- Riesgo de agrupaciones arbitrarias: Sin etiquetas, existe el riesgo de agrupar los datos de formas que no tienen sentido práctico.
Aprendizaje semi-supervisado
El aprendizaje semi-supervisado es un enfoque intermedio entre el aprendizaje supervisado y el no supervisado. Utiliza tanto datos etiquetados como datos no etiquetados para entrenar algoritmos. Normalmente, se combina una pequeña cantidad de datos etiquetados con una gran cantidad de datos no etiquetados. Este método es especialmente útil en situaciones donde la obtención de datos etiquetados es costosa o lleva tiempo, pero se dispone en abundancia de datos no etiquetados.
Aplicaciones del aprendizaje semi-supervisado
El aprendizaje semi-supervisado encuentra aplicaciones en diversas áreas, incluyendo:
- Procesamiento del Lenguaje Natural (PLN): Aplicada en tareas como el análisis de sentimientos, donde sólo una pequeña parte de los textos está etiquetada;
- Reconocimiento de voz: Mejora la precisión de los modelos de reconocimiento de voz utilizando datos de audio etiquetados y no etiquetados;
- Sistemas de recomendación: Mejora las recomendaciones utilizando datos parcialmente etiquetados de preferencias de usuario;
- Clasificación de imágenes: Utilizada para clasificar grandes conjuntos de imágenes donde sólo algunas están etiquetadas, reduciendo el esfuerzo del etiquetado manual;
- Diagnóstico médico: Ayuda a identificar enfermedades utilizando un pequeño conjunto de datos médicos etiquetados y un gran volumen de datos no etiquetados;
- Detección de fraudes: Aumenta la eficacia de los sistemas de detección de fraudes combinando transacciones etiquetadas con un gran número de transacciones no etiquetadas.
Ventajas
El aprendizaje semi-supervisado presenta varias ventajas importantes:
- Reducción de costes y tiempo: Requiere menos datos etiquetados, reduciendo significativamente el coste y el tiempo involucrados en la etiquetación manual;
- Mejor rendimiento: Puede resultar en un mejor rendimiento del modelo en comparación con el aprendizaje no supervisado, utilizando información de los datos etiquetados;
- Flexibilidad: Adecuada para muchos ámbitos donde los datos no etiquetados son abundantes, pero los datos etiquetados son pocos;
- Generalización: Mejora la capacidad de generalización del modelo al explorar patrones en datos no etiquetados.
Desafíos
El aprendizaje semi-supervisado también afronta algunos desafíos:
- Calidad de los datos no etiquetados: La eficacia depende de la calidad de los datos no etiquetados, ya que datos ruidosos o irrelevantes pueden perjudicar el rendimiento;
- Complejidad algorítmica: Los algoritmos pueden ser complejos y requerir mayor potencia computacional para procesar grandes volúmenes de datos no etiquetados;
- Etiquetado inicial: La selección y el etiquetado inicial de un conjunto de datos representativo es crucial y puede influir significativamente en el rendimiento del modelo;
- Evaluación del rendimiento: Evaluar y validar el rendimiento de modelos semi-supervisados puede ser complejo debido a la mezcla de datos etiquetados y datos no etiquetados.
Aprendizaje por refuerzo
El aprendizaje por refuerzo es un enfoque de machine learning en el que un agente aprende a tomar decisiones en un entorno dinámico para maximizar una recompensa acumulativa. A diferencia del aprendizaje supervisado y no supervisado, el aprendizaje por refuerzo se basa en la interacción continua del agente con el entorno, recibiendo feedback en forma de recompensas o castigos en función de las acciones realizadas. El agente ajusta su estrategia a lo largo del tiempo para mejorar su rendimiento, aprendiendo qué acción realizar en diferentes situaciones para obtener la mayor recompensa posible.
Aplicaciones del aprendizaje por refuerzo
El aprendizaje por refuerzo tiene una amplia gama de aplicaciones prácticas, entre las que se incluyen:
- Robótica: Desarrollar robots capaces de realizar tareas complejas como navegación autónoma, manipulación de objetos y tareas industriales;
- Juegos: Entrenar agentes para jugar a juegos como el ajedrez y videojuegos complejos, superando a los jugadores humanos;
- Sistemas de recomendación: Mejorar la personalización en sistemas de recomendación ajustando las sugerencias según el feedback continuo del usuario;
- Control del tráfico: Optimizar el control de los semáforos en las ciudades para reducir congestionamientos y mejorar el flujo del tráfico;
- Financiero: Desarrollar estrategias comerciales automatizadas que se ajustan dinámicamente al mercado para maximizar los beneficios;
- Gestión de recursos: Optimizar la asignación de recursos en centros de datos y redes de comunicación para mejorar la eficiencia y reducir costes;
- Salud: Desarrollar protocolos de tratamiento personalizados que se ajustan en función de la respuesta del paciente al tratamiento.
Ventajas
El aprendizaje por refuerzo presenta varias ventajas, entre las que destacamos:
- Adaptación continua: El agente puede adaptar sus acciones basándose en el feedback continuo del entorno, mejorando su rendimiento con el tiempo;
- Exploración: Equilibra la exploración de nuevas estrategias y la explotación de estrategias ya conocidas para optimizar la recompensa;
- Aplicabilidad en entornos dinámicos: Ideal para entornos en los que las condiciones cambian continuamente y la toma de decisiones en tiempo real es crucial.
Desafíos
A pesar de sus ventajas, el aprendizaje por refuerzo afronta algunos desafíos:
- Complejidad computacional: Requiere recursos computacionales significativos para el entrenamiento, especialmente en entornos complejos;
- Recompensas escasas: En muchos entornos, las recompensas pueden ser escasas y retrasadas, lo que dificulta que el agente aprenda las mejores acciones;
- Seguridad y confiabilidad: Garantizar que el agente tome decisiones seguras y fiables en entornos críticos es un desafío;
- Escalabilidad: Escalar soluciones de aprendizaje por refuerzo para problemas de gran escala con múltiples agentes puede ser complejo.
Integración del ML con los principios Kaizen
La integración del machine learning y la inteligencia artificial con los principios Kaizen representa una sinergia entre las tecnologías avanzadas y los métodos de mejora continua. Kaizen, palabra japonesa que significa «mejora continua», enfatiza la optimización de procesos, productos y servicios. Cuando se combina con el ML, Kaizen puede acelerar la eficiencia operacional y la innovación, proporcionando un enfoque estructurado hacia la excelencia.
Mejora continua en ML
La integración de los principios de la mejora continua en el machine learning proporciona un framework estructurado y eficiente para optimizar cada etapa del proceso, desde la identificación de oportunidades hasta la aplicación y mejora de los modelos de ML. Kaizen, con su enfoque en la optimización y el involucramiento de todo el equipo, puede ser una poderosa herramienta para impulsar la innovación y la eficacia en los proyectos de ML.
Esta sinergia puede impactar positivamente en las distintas fases del proyecto:
- Identificación de oportunidades de aplicación del ML: Al promover una cultura de análisis y de búsqueda continua por mejoras, Kaizen facilita la identificación de áreas en las que se puede aplicar el ML para resolver problemas u optimizar procesos;
- Gestión de proyectos: Kaizen y Lean ofrecen enfoques estructurados de gestión de proyectos que pueden apoyar la implementación de proyectos de ML, garantizando que cada etapa se ejecute de forma eficiente y con calidad;
- Recopilación y preparación de datos: Con su enfoque en datos y pruebas, Kaizen puede ayudar en el proceso de recopilación de datos, garantizando que sean de alta calidad y relevantes para los modelos;
- Entrenamiento y validación: Kaizen puede contribuir a la implementación de ciclos de entrenamiento y validación con feedback continuo, permitiendo ajustes rápidos y mejoras incrementales de los modelos;
- Evaluación del rendimiento: Establecer métricas claras y revisiones regulares para monitorizar el rendimiento de los modelos, identificando áreas para mejoras, es otra área donde Kaizen puede beneficiar a las organizaciones;
- Feedback y ajustes: La mejora continua también fomenta el uso de feedback de los usuarios y de los resultados operativos para ajustar los modelos y procesos.
Implementar los principios Kaizen en los proyectos de implementación de machine learning no sólo mejora la eficiencia de los procesos, sino que también promueve una cultura de innovación y adaptación continuas, fundamental para el éxito en entornos dinámicos y competitivos.
Excelencia operacional
La combinación del machine learning con los principios Kaizen puede contribuir significativamente a la excelencia operacional. El machine learning, con su capacidad para analizar grandes volúmenes de datos e identificar patrones ocultos, ofrece insights valiosos que pueden orientar las mejoras en los procesos operacionales. Cuando se aplican sistemáticamente y se alinean con los principios Kaizen, estas mejoras se vuelven aún más eficaces y sostenibles.
Por ejemplo, el ML puede utilizarse para monitorizar continuamente la eficiencia de una línea de producción, identificando los cuellos de botella y las variabilidades que afectan al rendimiento. Estos insights permiten que los equipos implementen mejoras, optimizando la productividad y la calidad. Además, las herramientas de machine learning desempeñan un papel relevante en el mantenimiento predictivo, ya que pueden predecir posibles problemas antes de que ocurran, permitiendo tomar medidas preventivas y reducir el tiempo de inactividad y los costes operacionales.
La integración de estas tecnologías también facilita la medición del impacto de los cambios implementados. Este enfoque basado en datos garantiza que las mejoras se basen en pruebas concretas, lo que aumenta la probabilidad de éxito y la sostenibilidad de los cambios.
Además, el uso del machine learning puede automatizar tareas repetitivas y operacionales, liberando a los empleados para que se concentren en actividades de mayor valor añadido.
En resumen, Kaizen facilita la implementación de la transformación digital, pero las tecnologías como la IA y el Business Analytics también pueden contribuir a la mejora continua en las organizaciones. Esta sinergia entre la tecnología y los principios Kaizen crea un entorno de trabajo más eficiente, ágil e innovador, esencial para las organizaciones del futuro. La aplicación conjunta de IA y Kaizen proporciona a las organizaciones un impulso significativo en su camino hacia la excelencia operacional.
¿Todavía tienes alguna duda sobre Machine Learning?
¿Por qué integrar los principios Kaizen en el ML?
Integrar los principios Kaizen en el Machine Learning (ML) ofrece varias ventajas significativas:
- Mejora continua: Kaizen enfatiza la mejora continua, lo que permite mejorar continuamente los modelos de ML;
- Eficiencia operacional: Optimiza los procesos y flujos de trabajo, reduciendo desperdicios y aumentando la eficiencia en las operaciones de ML;
- Innovación constante: Fomenta una cultura de innovación en la que se prueban y aplican constantemente nuevas ideas y técnicas;
- Participación de los empleados: Involucra a los equipos en los procesos de mejora, aumentando la motivación y el compromiso con la calidad y la eficiencia.
¿Cuáles son los tipos de machine learning menos conocidos?
Además de las categorías ampliamente conocidas, hay varios tipos menos conocidos de machine learning que se utilizan en nichos específicos o para resolver problemas particulares:
- Learning to Rank (L2R): Este método se utiliza principalmente en motores de búsqueda y sistemas de recomendación para clasificar elementos en un orden específico de relevancia o preferencia;
- Aprendizaje Few-shot:Este método permite que un modelo aprenda con muy pocos ejemplos de entrenamiento, generalmente sólo unos pocos ejemplos de cada clase;
- Aprendizaje Zero-shot: El aprendizajeZero-shot permite que a un modelo reconocer clases que no estaban presentes en el conjunto de entrenamiento. Esto se logra generalizando a partir de otras clases conocidas;
- Aprendizaje Multi-task:Un modelo se entrena para realizar múltiples tareas simultáneamente, compartiendo información entre tareas relacionadas para mejorar el rendimiento;
- Self-supervised Learning: El modelo genera sus propias etiquetas a partir de datos no etiquetados, generalmente utilizando la estructura interna de los datos como supervisión;
- Aprendizaje activo: El modelo interactúa con un oráculo (como un humano) para etiquetar nuevos datos que se consideran más informativos y que pueden mejorar el rendimiento del modelo;
- Aprendizaje por refuerzo con transferencia (Transfer RL): Combina el aprendizaje por refuerzo con la transferencia de conocimientos de un dominio a otro, lo que permite a los modelos aprovechar los conocimientos adquiridos en tareas anteriores;
- Aprendizaje federado:Permite que varios dispositivos entrenen un modelo de ML de forma colaborativa sin compartir datos entre sí, preservando la privacidad de los datos.
¿Cuál es la diferencia entre streaming y batch learning en ML?
La principal diferencia entre streaming y batch learning en ML reside en la forma como se procesan los datos. En el streaming, los datos se procesan en flujos continuos, y el modelo se actualiza a medida que llegan nuevos datos. Esto permite que el modelo se adapte rápidamente a los cambios en los datos a lo largo del tiempo, siendo ideal para sistemas donde la memoria y el almacenamiento son limitados, ya que procesa pequeños lotes de datos a la vez. Entre las aplicaciones comunes del streaming se encuentran los sistemas de recomendación, el análisis de redes sociales y la detección de fraudes en tiempo real.
Por otro lado, en el batch learning, todos los datos se procesan de una vez, y el modelo se entrena con el conjunto completo de datos. Esto garantiza un análisis más estable y completo de los datos disponibles, resultando en modelos más robustos. Sin embargo, este enfoque requiere más memoria y poder computacional, ya que todos los datos se cargan y procesan de una vez. El batch learning es adecuado para tareas de predicción, clasificación y análisis de datos históricos.
¿Cuáles son las principales métricas para evaluar modelos de machine learning?
Para evaluar eficazmente los modelos de machine learning, es necesario comprender y utilizar una variedad de métricas clave, que varían en función del tipo de tarea (por ejemplo, clasificación, regresión, agrupamiento). Aquí están algunas de las principales métricas para distintos tipos de tareas de ML:
Métricas de clasificación:
- Matriz de confusión: Tabla que resume el rendimiento de un modelo de clasificación mostrando verdaderos positivos, verdaderos negativos, falsos positivos y falsos negativos. Proporciona una visión detallada de los errores del modelo, por ejemplo:
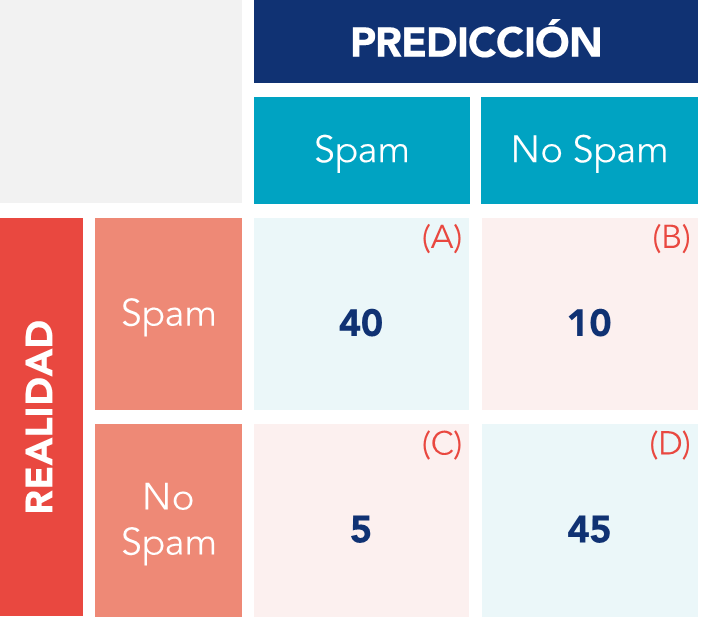
- Extactitud: Proporción de predicciones correctas (tanto positivas como negativas) con relación al total de predicciones. Utilizada principalmente en problemas de clasificación. Como ejemplo ilustrativo de estas métricas, imaginemos un modelo que clasifica correos electrónicos como «spam» o «no spam». En este caso, la exactitud se referiría al porcentaje de correos clasificados correctamente. Utilizando los datos de la tabla siguiente, la exactitud del modelo sería (40+45) / 100 = 85%;
- Precisión: Proporción de verdaderos positivos con relación al total de positivos previstos. En otras palabras, mide el porcentaje de las predicciones de la clase positiva que estaban realmente correctas. En nuestro ejemplo, el modelo clasificó 45 e-mails como spam (A + C), de los cuales 40 (A) pertenecen efectivamente a la clase positiva. En este caso, la precisión será de 40/45 = 89%;
- Recall (Sensibilidad): Relación de verdaderos positivos y el total de verdaderos positivos. Es decir, cuántas muestras de la clase positiva fueron identificadas por el modelo. Utilizando nuestro ejemplo, de los 50 e-mails de spam (A + B), sólo 40 fueron identificados por el modelo (A), existiendo 10 que fueron clasificados incorrectamente como no spam (B). El recall de nuestro modelo será entonces del 40/50 = 80%;
- F1-Score: Media armónica entre precisión y recall. Útil para equilibrar la precisión y el recall en problemas de clasificación. Este valor muestra si el modelo tiene una buena capacidad para predecir correctamente el spam, es decir, resulta útil cuando se pretende garantizar no sólo la precisión, sino también la capacidad de identificación una proporción significativa de correos spam reales. En nuestro caso, este valor sería de aproximadamente del 84%.
Métricas de regresión:
- Error cuadrático medio (Mean Squared Error – MSE/ECM):Promedio de los cuadrados de los errores o diferencias entre los valores previstos y los valores reales. Utilizada principalmente en problemas de regresión;
- R-Cuadrado (Coeficiente de determinación): Mide la proporción de la varianza de los datos dependientes que es previsible a partir de las variables independientes. Se utiliza para evaluar el ajuste de los modelos de regresión.
Métricas de agrupamiento (Clustering):
- Índice de silueta: Mide la similitud de un objeto con su propio cluster en comparación con otros clusters;
- Índice de Davies-Bouldin: Mide la relación media de similitud de cada cluster con el cluster más similar a él;
- Índice de Rand ajustado (ARI): Mide la similitud entre dos conglomerados de datos, ajustando por la agrupación aleatoria de elementos.